

使用 k3s 搭建 cilium + istio 实验环境
使用 k3s 搭建 cilium + istio 实验环境

notion 文章发布到 hugo
notion文章同步到hugo
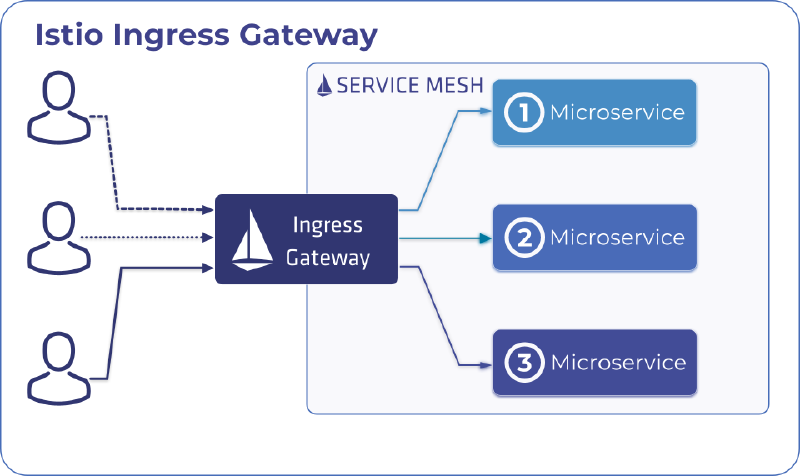
istio-ingressgateway 学习
使用 istio-ingressgateway 暴露服务

使用docker部署caddy暨buildx编译多架构镜像
使用docker部署caddy暨buildx编译多架构镜像

Coredns 添加主机名解析,无法解析
Coredns 添加主机名解析,nodelocaldnscache无法解析


kubeadm 编译修改证书有效期
修改kubeadm的证书有效期

